13 KiB
+++ title = "How we fixed Synapse's scalability!" path = "/blog/2020/11/03/how-we-fixed-synapse-s-scalability" aliases = ["/blog/2020/11/03/how-we-fixed-synapses-scalability"]
[taxonomies] author = ["Matthew Hodgson"] category = ["Releases"]
[extra] image = "https://matrix.org/blog/img/2020-11-03-synapse5.jpg" +++
{kind=link}
Hi all,
We had a major break-through in Synapse 1.22 which we want to talk about in more detail: Synapse now scales horizontally across multiple python processes.
Horizontal scaling means that you can support more users and traffic by adding in more python processes (spread over more machines, if necessary) without there being a single bottleneck which all the traffic is passing through - as opposed to vertical scaling where you make things go faster overall by making the bottleneck go faster.
After many years of having to vertically scale Synapse (by trying to make the main process go faster) we’re now finally at the point where you can configure Synapse so that messages no longer flow through the main process - eliminating the bottleneck entirely. What’s more, the Matrix.org homeserver has now been successfully running in this config and enjoying the massive scalability improvements for the last 2 weeks! Huge kudos goes to Erik and the wider Synapse team for pulling this off.
Some readers might wonder how this ties in with Dendrite entering beta, given one of Dendrite’s design goals is full horizontal scalability. The answer is that we’re very much using Dendrite for experimentation and next-gen stuff at the moment (currently focused more on scaling downwards for P2P rather than scaling upwards for megaservers) - while Synapse is the stable and long-term supported option.
So, that’s the context - now over to Erik with more than you could possibly ever want to know about how we actually did it...
Background
Synapse started life off back in 2014 as a single monolithic python process, and for quite a while we made it scale by adding more and more in-memory caches to speed things up by avoiding hitting the database (at the expense of RAM). It looked like this:

Eventually the caches stopped helping and we needed more than one thread of execution in order to spread CPU across multiple cores. Python’s Global Interpreter Lock (GIL) means that Python can mainly only use one CPU core at a time, so starting more threads doesn’t help with scalability - you have to run multiple processes.
Now, the vast majority of the work that Synapse does is related to “streams”.
These are append only sequences of rows, such as the events stream, typing
stream, receipts stream, etc. When a new event arrives (for example) we write
it to the events stream, and then notify anything waiting that there has been
an update. The /sync endpoint, for instance, will wait for updates to streams
and send them down to long-polling Matrix clients.
Streams support being added to concurrently, so have a concept of the “persisted up-to position”. This is the point where all rows before that point have finished persisting. Readers only read up to the current “persisted up-to position”, so that they don’t skip updates that haven’t finished persisting at that point. (E.g. if two events A and B get assigned positions 5 and 6, but B finishes persisting first, then the persisted up to position will remain at 4 until A finishes persisting and then it jumps to 6).
To split any meaningful amount of work into separate processes, we need to add a mechanism where processes can be told that updates to streams have happened (otherwise they’d have to repeatedly poll the DB, which would be deeply inefficient). The architecture ended up being one where we had the “main” process that streams updates via a custom replication protocol (initially long-polling HTTP; later custom TCP) to any number of “worker” processes. This meant that we could move sync stream handling (and other read apis) off the main process and onto workers, but also that all database writes had to go through the single main process (as it was a star topology, the main process could talk to all workers but workers could only talk to the main process and not each other).

As an aside: cache invalidations also had to be streamed down the replication connections, which has the side effect that we could only cache things that would only be invalidated on the main process.
We continued to move more and more read APIs out onto separate workers. We also added workers in front of the main process that would e.g. handle the creation of the new events, authenticating, etc, and then call out to the main process with the event for it to persist the event.
Moving writes off the main process
Eventually we ran out of stuff to move out of the main process that didn’t involve writing to the DB. To write stuff from other processes we needed a way for the workers to stream updates to each other. The easiest and most obvious way was to just use Redis and its pub/sub support.

This almost allowed us to move writing of a particular stream to a different worker, except writing to streams generally also meant invalidating caches which in itself requires writing to a stream. We needed a way of writing to the cache invalidation stream from multiple workers at once.
Sharding the cache invalidation thankfully turned out to be easy, as workers would simply call the cache invalidation function whenever they get an invalidation notice over replication. In particular, the ordering of invalidations from different workers doesn’t matter and so there isn’t a need to calculate a single “persisted up-to position”. Sharding then just becomes a case of adding the name of the worker that is writing the update to the replication stream, and then workers reading from it can basically treat the cache stream the same as if they were multiple streams, one per worker.
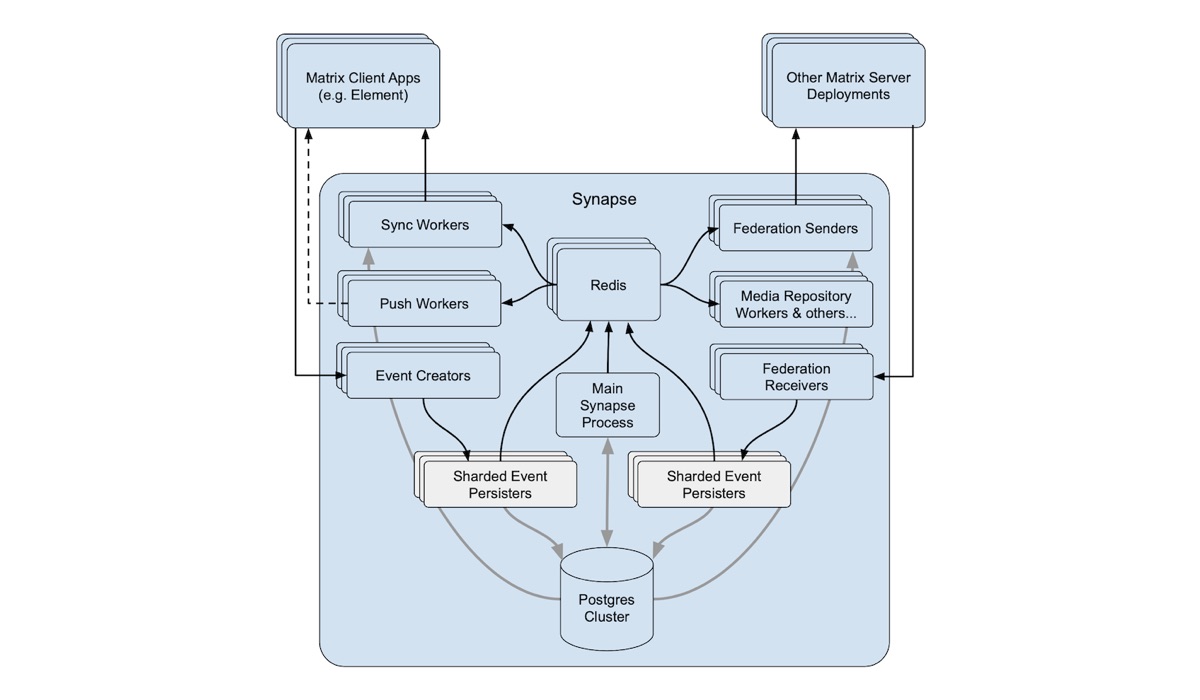
This then unlocks the ability to move writing of streams off the main process and onto different workers - and so we added the “event persister” worker for offloading the main event stream off the main process:

Sharding the events stream
Eventually the worker responsible for doing nothing but persisting events started maxing out CPU. This meant that we had to look at sharding the events stream, i.e. writing to it from multiple workers.
This is more complicated than sharding the cache invalidation stream as the ordering of the events does matter; we send them down sync streams, in order, with a token that indicates where the sync stream is up to in the events stream. This means that workers need to be able to calculate a “persisted up-to position” when getting updates from different workers.
The easiest way of doing that is to simply set the persisted up-to position as the minimum position received over federation from all active writers. This works, except events would only be processed after all other writers have subsequently written events (to advance the persisted position past the point at which the event was written), which can add a lot of latency depending on how often events are written.
A refinement is to note that if you have a persisted up-to position of 10, then receive updates at sequential positions 11, 12, 13 and 14, you know that everything between 10 and 14 has finished persisting (as you received updates about them), and so can set the persisted up-to position to 14. Annoyingly, it’s not required that positions are sequential without gaps (due to various technical considerations), and so in the worst case this still has the same problems as the naïve solution.
To avoid these problems we change the persisted up-to position to be a vector clock of positions; tracking a vector of positions - one per writer. This still allows answering the query of “get all events after token X” (as events are written with the position and the name of the writer). The persisted up-to position is then calculated by just tracking the last position seen to arrive over replication from each writer.
This allows writing events from multiple workers, while ensuring that other workers can correctly keep track of a “persisted up-to position”. Then it's just a matter of inspecting the code to ensure that it does not assume that it is the only writer to the stream. In the case of writing to the events stream, we note that the function persisting events assumes it's the only writer for a given room, so when sharding we have to ensure that there are no concurrent writes to the same room. This is most easily done by sharding based on room ID, and ensuring that the mapping of room ID to worker does not change (without coordination).
The only thing left is to then encode the vector clock position into the sync
tokens. We want to ensure that these tokens are not too long, as they get
included as query string parameters (e.g. the since= parameter of /sync).
By assigning persistent unique integer IDs to workers the vector clock can be
persisted as a sequence of pairs of integers, which is relatively few bytes so
long as we don’t have too many workers writing to the events stream. We can
further reduce the size of the tokens by calculating an integer “persisted
up-to position” as we did before, encoding that and only including positions
for workers that are larger than the integer persisted upto position. (The
idea here is that most of the time only a small number of workers will be
ahead of the calculated persisted up-to position, and so we only need to
encode those).
And this is what we have today:

The major limitation of the current situation is that you can’t dynamically add/remove workers which persist events, as the sharding by room ID is calculated at startup, and so changing it requires restarting the whole system. This could be replaced by any system that allowed coordination over which persister is allowed to write to a room at any given point. However this is likely tricky to get right in practice, but would allow dynamic auto scaling of deployments, or automatically recovering from a worker that gets wedged/dies.
Finally, it’s worth noting that sharding event persisters isn’t the only performance work that’s been going on - switching everything over to python 3 and async twisted has helped, along with lots of smaller optimisations on the hot paths, and further rebalancing workers (e.g. moving background jobs off the master process to dedicated workers). We’ve also benefited a lot from the maintainability of rolling out mypy typing throughout the codebase. And next up, we’ll be going back to speeding up the codebase as a whole - starting with algorithmic state resolution improvements! 🎉
Performance
So, how does it stack up?
Here’s the send time heatmap on Matrix.org showing the step change on Oct 16th when we rolled out the second event persister (full disclosure: this also coincides with moving background processes off the main Synapse process to a background worker). As you can see, we go from messages being spread over a huge range of durations (up to several seconds) to the sweet spot being 50ms or less - a spectacular improvement!

Meanwhile, here’s the actual CPU utilisation as we split the traffic from a single event persister (yellow) to two persisters (one yellow, one blue), showing the sharding beautifully horizontally balancing CPU between the two active/active worker processes:

We’ve yet to loadtest to see just how fast we can go now (before we start hitting bottlenecks on the postgres cluster), but it sure feels good to have all our CPU headroom back on Matrix.org again, ready for the next wave of users to arrive.
Conclusion
So there you have it: folks running massive homeservers (50K+ concurrent users) like Matrix.org (and cough various high profile public sector deployments) are no longer held hostage by the bottleneck of the main synapse process and should feel free to experiment with setting up event persister workers to handle high traffic loads. Otherwise, if you can spread your users over smaller servers, that’s also a good bet (assuming they don’t have massively overlapping room membership, like we see on Matrix.org.)
The current worker documentation is up-to-date, although does assume you are already very familiar with how to administer Synapse. It’s also very much subject to change, as we keep adding new workers and improving the architecture. However, now is a pretty good time to get involved if you’re interested in large-scale Matrix deployments.
-- The Synapse Team